Simple Python Project 实录 —— Enum2Magic
前言
很高兴和大家分享一下自己完成一个小项目的心得,希望能给不光自己同样是读者带来一定的帮助。
相信大家也会和我遇到同样的情况。当我们脑海里有了一些想法的时候,却不知道如何利用我们所知的技能去实现这一想法。具体一点,如何写下我们的第一行代码,其实这个过程是非常纠结的。真是万事开头难啊!
不过没关系,随着经验的积累,会慢慢摸索到自己的一套方法论的。接下来,我会分享我个人的一个实际例子(从构思到完成整个目标)。
问题
这个例子是来自工作当中。由于一些历史原因,工作中用的Java1.4版本
吐嘈:话说1.5和1.4差别真的不是一点点,希望能早日走出1.4的魔抓!
我发现代码里很多的硬编码的ID,比如:
public static int Jan = 0x00;
public static int Feb = 0x01;
public static int Mar = 0x02;
后来才发现,原来Java1.4不支持枚举类型(T__T)。这将会面临一个问题。如果需要增、删、改某个ID的值的话,很可能会需要修改一大片ID。这需要付出很大的人力代价,而且非常容易出错。
为了很方便的解决这一问题,我决定写一个脚本自动的帮助我构建这些硬编码的ID。
那么在开始写第一行代码的时候,我通常会做以下几件事:
- 想清楚自己的软件功能(明确需求)
- 简单的构思一下所需要的实现方法(构思架构)
- 如果问题的组面很多,把他拆分和抽象出一些相对独立的单元(Breakdown)
- 尽量避免自己从新造轮子(寻找一些现成的解决方案)
关于3和4两点其实都是由第二点延伸出来的;关于第四点:
1. 如果你想锻zhe炼mo自己,最好是尝试一下自己造个轮子看看,然后比照一些现有的解决方案。你就会发现自己的构思与别人的构思差距在哪。
2. 如果是一个比较庞大的项目且时间比较紧张,可以根据需要选择合适的现有解决方案
需求分析
首先我们可以列举一下预期的效果:
A:一个命令行工具
使用方法大致如下:$ enum2magic <inputfile>
B:灵活的输出格式设定
我模仿Jekyll的模板定义,将输入文件的格式分为Header和Body。Header的格式如下:
---
key1 : value1
key2 : value2
# ...
---
C:解析语法尽量简单
为了保持语法的简介,我直接借用了C语言的枚举类型的格式(实际解析的句法并不需要那么严格)。因此Body的格式如下:
typedef enum Month{
M_January = 0, // bala...
// some comments
M_February
// ...
};
D:最终目标
INPUT:
---
# 输出路径
target_name: out.txt
# 输出模板
target_template: {element} = {value};
# 忽略前缀
ignore_prefix: M_
---
typedef enum Month{
M_January = 0, // bala...
// some comments
M_February
// ...
};
OUTPUT:
January = 0; // bala...
// some comments
February = 1;
// ...
目标看上去实现起来非常复杂:
- 需要解析配置
- 解析C风格的enum句法
- 各种异常case
然而实际上,只要找准方向,把问题简化,最后逐个击破也就不复杂了!接下来是重头戏哦!
构思架构
分析这个问题的时候,可以很容易发现,这个程序有两部分要解析:
- Header -> 头部(配置)
- Body -> 正文(内容)
另外,我发现无论是Header还是Body,他们的结构其实都非常类似。
除去一些个别情况,基本都是XXX operator XXX格式。
Tips:构思初期没有必要考虑好各种意外的case,而是抓住更宏观的东西再一层一层具体细化(如同绘画,先勾勒轮廓再具体刻画细节)
于是,我想要是有个东西可以区分这两类,告诉我什么时候是Header和Body那么就容易多了。紧接着,我就想到了有限状态机-FSM。
闲话:FSM这玩意非常强大,上学的时学Verilog的时候,老师曾经给我们简单介绍了一下如何利用FSM思路做一个只有几个指令的CPU!当时把我看呆了!
状态迁移图
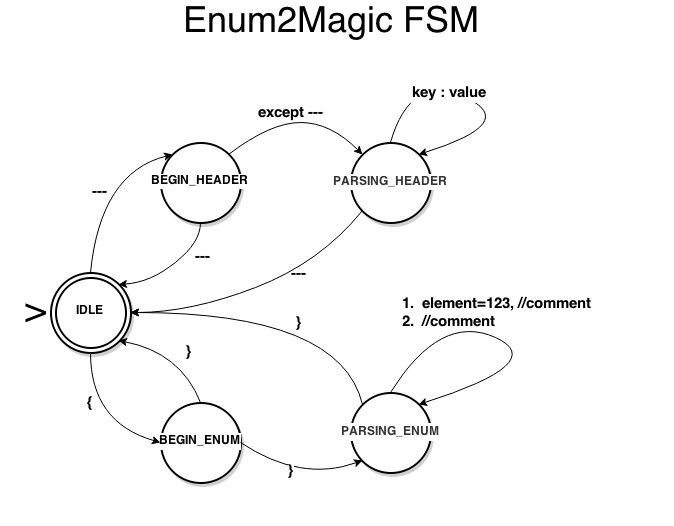
这里一共分为5个状态:
- IDLE 空闲
- BEGIN_HEADER 开始解析头部
- PARSING_HEADER 解析头部
- BEGIN_ENUM 开始解析枚举内容
- PARSING_ENUM 解析枚举内容
刚开始构思的时候只有1、3、5三个状态,且每个解析过程也非常简单——直接打印需要解析的内容文字。
后来发现在解析的过程中会经常冒出一些起止字符如:---,原因是我的状态机解析过程如下:
- 读入一行
- 迁移状态
- 分发事件
因此,当读入的是起止字符将直接进入解析状态,导致在解析状态输出起止字符。为了保持事件处理任务的独立性,因此增加了两个过度状态。
Tips: 在写代码的时候,我会立刻测试我每增加的一个功能。这可以让你每一步都会走的脚踏实地!
Breakdown
大的框架搭好之后就是一些小细节了,其主要是Header和Body两部分。
A:Header解析
Header的解析其实非常简单。由于其格式是key : value,我就直接把字符串从冒号处分割成左右两部分。最后,把读取的配置保存在一个配置Dict里。这个时候再来处理异常Case就相对简单一点了。
B:Body解析
这部分会稍微有一点点复杂,但也不难。首先,我对格式做了个分析:
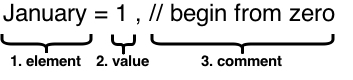
我将格式分为三大块:
- element
- value
- comment
比较麻烦的事情就是这三种之一都可能没有。还是那个老思路,把一个问题分解成几个小问题,然后逐个击破。 其实,每个Body都可以看作是这三块的一个线性组合。因此,我选择从右向左剥离,每次提取一小块的方法把这块逐个解析到。
为了使得输出格式的灵活性,我借用了string.format()的模板标记完成格式化的输出。
总结
程序的主要内容到这里也就基本介绍完了,其实总体来说并不是很复杂。实际实现过程中,我还利用了OOP的思路完成了模块的封装。总结一下,我想有一下几点需要牢记的:
- 分析好自己的需求
- 从宏观考虑并拆分各个组面
- 把大问题划分为小问题的组合并逐个击破
- 测试与开发交替进行
具体的代码已经放在Github.com上了,文档工作会在之后慢慢补充。最后,如有不妥指出还望指正,我愿意与大家共同学习进步!
practice